分解质因数
引入¶
给定一个正整数 \(N \in \mathbf{N}_{+}\),试快速找到它的一个 非平凡因数。
考虑朴素算法,因数是成对分布的,\(N\) 的所有因数可以被分成两块,即 \([2, \sqrt N]\) 和 \([\sqrt N+1,N)\)。只需要把 \([2, \sqrt N]\) 里的数遍历一遍,再根据除法就可以找出至少两个因数了。这个方法的时间复杂度为 \(O(\sqrt N)\)。
当 \(N\ge10^{18}\) 时,这个算法的运行时间我们是无法接受的,希望有更优秀的算法。一种想法是通过随机的方法,猜测一个数是不是 \(N\) 的因数,如果运气好可以在 \(O(1)\) 的时间复杂度下求解答案,但是对于 \(N\ge10^{18}\) 的数据,成功猜测的概率是 \(\frac{1}{10^{18}}\), 期望猜测的次数是 \(10^{18}\)。如果是在 \([2,\sqrt N]\) 里进行猜测,成功率会大一些。我们希望有方法来优化猜测。
朴素算法¶
最简单的算法即为从 \([2, \sqrt N]\) 进行遍历。
vector<int> breakdown(int N) {
vector<int> result;
for (int i = 2; i * i <= N; i++) {
if (N % i == 0) { // 如果 i 能够整除 N,说明 i 为 N 的一个质因子。
while (N % i == 0) N /= i;
result.push_back(i);
}
}
if (N != 1) { // 说明再经过操作之后 N 留下了一个素数
result.push_back(N);
}
return result;
}
def breakdown(N):
result = []
for i in range(2, int(sqrt(N)) + 1):
if N % i == 0: # 如果 i 能够整除 N,说明 i 为 N 的一个质因子。
while N % i == 0:
N //= i
result.append(i)
if N != 1: # 说明再经过操作之后 N 留下了一个素数
result.append(N)
return result
我们能够证明 result 中的所有元素均为 N 的素因数。
证明 result 中均为 \(N\) 的素因数
首先证明元素均为 \(N\) 的素因数:因为当且仅当 N % i == 0 满足时,result 发生变化:储存 \(i\),说明此时 \(i\) 能整除 \(\frac{N}{A}\),说明了存在一个数 \(p\) 使得 \(pi=\frac{N}{A}\),即 \(piA = N\)(其中,\(A\) 为 \(N\) 自身发生变化后遇到 \(i\) 时所除的数。我们注意到 result 若在 push \(i\) 之前就已经有数了,为 \(R_1,\,R_2,\,\ldots,\,R_n\),那么有 N \(=\frac{N}{R_1^{q_1}\cdot R_2^{q_2}\cdot \cdots \cdot R_n^{q_n}}\),被除的乘积即为 \(A\))。所以 \(i\) 为 \(N\) 的因子。
其次证明 result 中均为素数。我们假设存在一个在 result 中的合数 \(K\),并根据整数基本定理,分解为一个素数序列 \(K = K_1^{e_1}\cdot K_2^{e_2}\cdot\cdots\cdot K_3^{e_3}\),而因为 \(K_1 < K\),所以它一定会在 \(K\) 之前被遍历到,并令 while(N % k1 == 0) N /= k1,即让 N 没有了素因子 \(K_1\),故遍历到 \(K\) 时,N 和 \(K\) 已经没有了整除关系了。
值得指出的是,如果开始已经打了一个素数表的话,时间复杂度将从 \(O(\sqrt N)\) 下降到 \(O(\sqrt{\frac N {\ln N}})\)。去 筛法 处查阅更多打表的信息。
例题:CF 1445C
Pollard Rho 算法¶
引入¶
而下面复杂度复杂度更低的 Pollard-Rho 算法是一种用于快速分解非平凡因数的算法(注意!非平凡因子不是素因子)。而在此之前需要先引入生日悖论。
生日悖论¶
不考虑出生年份(假设每年都是 365 天),问:一个房间中至少多少人,才能使其中两个人生日相同的概率达到 \(50\%\)?
解:假设一年有 \(n\) 天,房间中有 \(k\) 人,用整数 \(1, 2,\dots, k\) 对这些人进行编号。假定每个人的生日均匀分布于 \(n\) 天之中,且两个人的生日相互独立。
设 k 个人生日互不相同为事件 \(A\), 则事件 \(A\) 的概率为
至少有两个人生日相同的概率为 \(P(\overline A)=1-P(A)\)。根据题意可知 \(P(\overline A)\ge\frac{1}{2}\), 那么就有 \(1 \times \frac{n-1}{n} \times \dots \times \frac{n-k+1}{n} \le \frac{1}{2}\)
由不等式 \(1+x\le e^x\) 可得
然而我们可以得到一个不等式方程,\(e^{-\frac{k(k-1)}{2n}}\le 1-p\),其中 \(p\) 是一个概率。
将 \(n=365\) 代入,解得 \(k=23\)。所以一个房间中至少 23 人,使其中两个人生日相同的概率达到 \(50\%\), 但这个数学事实十分反直觉,故称之为一个悖论。
当 \(k>56\),\(n=365\) 时,出现两个人同一天生日的概率将大于 \(99\%\)。那么在一年有 \(n\) 天的情况下,当房间中有 \(\frac{1}{2}(\sqrt{8n\ln 2+1}+1)\approx \sqrt{2n\ln 2}\) 个人时,至少有两个人的生日相同的概率约为 \(50\%\)。
考虑一个问题,设置一个数据 \(n\),在 \([1,1000]\) 里随机选取 \(i\) 个数(\(i=1\) 时就是它自己),使它们之间有两个数的差值为 \(k\)。当 \(i=1\) 时成功的概率是 \(\frac{1}{1000}\),当 \(i=2\) 时成功的概率是 \(\frac{1}{500}\)(考虑绝对值,\(k_2\) 可以取 \(k_1-k\) 或 \(k_1+k\)),随着 \(i\) 的增大,这个概率也会增大最后趋向于 1。
利用最大公约数求出一个约数¶
\(n\) 和某个数的最大公约数一定是 \(n\) 的约数,即 \(\forall k \in\mathbf{N}_{+},\gcd(k,n) \mid n\),只要选适当的 \(k\) 使得 \(1<\gcd(k,n)< n\),就可以求得 \(n\) 的一个约数 \(\gcd(k,n)\)。满足这样条件的 \(k\) 不少,\(n\) 有若干个质因子,每个质因子及其大部分倍数都是可行的。
我们通过 \(f(x)=(x^2+c)\bmod n\) 来生成一个序列 \(\{x_i\}\):随机取一个 \(x_1\),令 \(x_2=f(x_1),x_3=f(x_2),\dots,x_i=f(x_{i-1})\)。其中 \(c\) 是一个随机选取的常数。
举个例子,设 \(N=50,c=2,x_1=1\),\(f(x)\) 生成的数据为
可以发现数据在 \(3\) 以后都在 \(11,23,31\) 之间循环。如果将这些数如下图一样排列起来,会发现这个图像酷似一个 \(\rho\),算法也因此得名 rho。
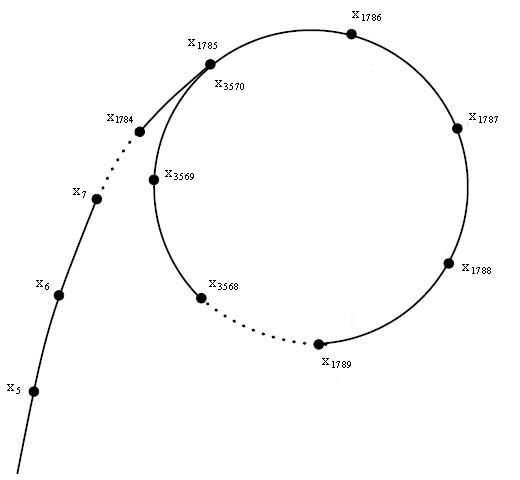
选择 \(f(x)=(x^2+c)\bmod n\) 这个函数生成序列,是因为它有一个性质:\(\forall x \equiv y \pmod p, f(x) \equiv f(y) \pmod p\),其中 \(p \mid n\)。
证明
若 \(x\equiv y \pmod p\),则可以将它们表示为 \(x=k_1p+a\),\(y=k_2p+a\),满足 \(k_1,k_2,a\in \mathbb{Z},a\in \left[0,p\right)\)。
\(f(x)=(x^2+c) \bmod n\),因此 \(f(x)=x^2+c-kn\),其中 \(k \in \mathbb{Z}\)。
同理,\(f(y) \equiv a^2+c \pmod p\),因此 \(f(x) \equiv f(y) \pmod p\)。
根据生日悖论,生成的序列中不同值的数量约为 \(O(\sqrt{n})\) 个。设 \(m\) 为 \(n\) 的最小非平凡因子,显然有 \(m\leq \sqrt{n}\)。
将 \(\{x_i\}\) 中每一项对 \(m\) 取模,我们得到了一个新序列 \(\{y_i\}\)(当然也可以写作 \(\{x_i \bmod m\}\)),并且根据生日悖论可以得知新序列中不同值的个数约为 \(O(\sqrt{m})\leq O(n^{\frac{1}{4}})\)。
因此,我们可以期望在 \(O(n^{\frac{1}{4}})\) 的时间内找到两个位置 \(i,j\),使得 \(x_i\neq x_j\wedge y_i=y_j\),这意味着 \(n \nmid |x_i−x_j| \wedge m \mid |x_i−x_j|\),我们可以通过 \(\gcd(n, |x_i-x_j|)\) 获得 \(n\) 的一个非平凡因子。
同理,任何满足 \(\forall x \equiv y \pmod p, f(x) \equiv f(y) \pmod p\) 的函数 \(f(x)\)(例如多项式函数)都可以用在此处,且我们希望它对大部分初始值尽可能快地进入循环、循环周期尽可能短(但对于一个合数与其任一质因子,循环周期长度不能相同,否则 Pollard Rho 算法将无法分离出这个因子)。
一般选择 \(x^2+c\) 生成序列,原因是它满足上述条件,且运行效率较高。同时,每次调用函数都将 \(c\) 设置为随机常数可以保证分解失败后重新分解的成功率。
性质¶
我们期望枚举 \(O(\sqrt{m})\) 个 \(i\) 来分解出 \(n\) 的一个非平凡因子 \(\gcd(|x_i−x_j|,n)\),因此。Pollard-rho 算法能够在 \(O(\sqrt{m})\) 的期望时间复杂度内分解出 \(n\) 的一个非平凡因子,通过上面的分析可知 \(O(\sqrt{m})\leq O(n^{\frac{1}{4}})\),那么 Pollard-rho 算法的总时间复杂度为 \(O(n^{\frac{1}{4}})\)。
下面介绍两种实现算法,两种算法都可以在 \(O(\sqrt{m})\) 的时间复杂度内完成。
实现¶
Floyd 判环¶
假设两个人在赛跑,A 的速度快,B 的速度慢,经过一定时间后,A 一定会和 B 相遇,且相遇时 A 跑过的总距离减去 B 跑过的总距离一定是圈长的 n 倍。
设 \(a=f(1),b=f(f(1))\),每一次更新 \(a=f(a),b=f(f(b))\),只要检查在更新过程中 a、b 是否相等,如果相等了,那么就出现了环。
我们每次令 \(d=\gcd(|x_i-x_j|,n)\),判断 d 是否满足 \(1< d< n\),若满足则可直接返回 \(d\)。由于 \(x_i\) 是一个伪随机数列,必定会形成环,在形成环时就不能再继续操作了,直接返回 n 本身,并且在后续操作里调整随机常数 \(c\),重新分解。
基于 Floyd 判环的 Pollard-Rho 算法
ll Pollard_Rho(ll N) {
ll c = rand() % (N - 1) + 1;
ll t = f(0, c, N);
ll r = f(f(0, c, N), c, N);
while (t != r) {
ll d = gcd(abs(t - r), N);
if (d > 1) return d;
t = f(t, c, N);
r = f(f(r, c, N), c, N);
}
return N;
}
import random
def Pollard_Rho(N):
c = random.randint(1, N - 1)
t = f(0, c, N)
r = f(f(0, c, N), c, N)
while t != r:
d = gcd(abs(t - r), N)
if d > 1:
return d
t = f(t, c, N)
r = f(f(r, c, N), c, N)
return N
倍增优化¶
使用 \(\gcd\) 求解的时间复杂度为 \(O(\log N)\),频繁地调用会使算法运行地很慢,可以通过乘法累积来减少求 \(\gcd\) 的次数。如果 \(1< \gcd(a,b)\),则有 \(1< \gcd(ac,b)\),\(c\in \mathbf{N}_{+}\),并且由 欧几里得算法 有 \(1< \gcd(ac \bmod b,b)=\gcd(ac,b)\)。
我们每过一段时间将这些差值进行 \(\gcd\) 运算,设 \(s=\prod|x_0-x_j|\bmod n\),如果某一时刻得到 \(s=0\) 那么表示分解失败,退出并返回 \(n\) 本身。每隔 \(2^k-1\) 个数,计算是否满足 \(1< \gcd(s, n) < n\)。此处取 \(k=7\),可以根据实际情况进行调节。
注意到在环上更容易分解出因数,我们可以先迭代一定的次数。
实现
ll Pollard_Rho(ll x) {
ll t = 0;
ll c = rand() % (x - 1) + 1;
// 加速算法,这一步可以省略
for (int i = 1; i < 1145; ++i) t = f(t, c, x);
ll s = t;
int step = 0, goal = 1;
ll val = 1;
for (goal = 1;; goal <<= 1, s = t, val = 1) {
for (step = 1; step <= goal; ++step) {
t = f(t, c, x);
val = val * abs(t - s) % x;
// 如果 val 为 0,退出重新分解
if (!val) return x;
if (step % 127 == 0) {
ll d = gcd(val, x);
if (d > 1) return d;
}
}
ll d = gcd(val, x);
if (d > 1) return d;
}
}
from random import randint
from math import gcd
def Pollard_Rho(x):
c = randint(1, x-1)
s = t = f(0, c, x)
goal = val = 1
while True:
for step in range(1, goal+1):
t = f(t, c, x)
val = val * abs(t - s) % x
if val == 0:
return x #如果 val 为 0,退出重新分解
if step % 127 == 0:
d = gcd(val, x)
if d > 1:
return d
d = gcd(val, x)
if d > 1:
return d
s = t
goal <<= 1
val = 1
对于一个数 \(n\),用 Miller Rabin 算法 判断是否为素数,如果是就可以直接返回了,否则用 Pollard-Rho 算法找一个因子 \(p\),将 \(n\) 除去因子 \(p\)。再递归分解 \(n\) 和 \(p\),用 Miller Rabin 判断是否出现质因子,并用 max_factor 更新就可以求出最大质因子了。由于这个题目的数据过于庞大,用 Floyd 判环的方法是不够的,这里采用倍增优化的方法。
实现
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
int t;
long long max_factor, n;
long long gcd(long long a, long long b) {
if (b == 0) return a;
return gcd(b, a % b);
}
long long quick_pow(long long x, long long p, long long mod) { // 快速幂
long long ans = 1;
while (p) {
if (p & 1) ans = (__int128)ans * x % mod;
x = (__int128)x * x % mod;
p >>= 1;
}
return ans;
}
bool Miller_Rabin(long long p) { // 判断素数
if (p < 2) return 0;
if (p == 2) return 1;
if (p == 3) return 1;
long long d = p - 1, r = 0;
while (!(d & 1)) ++r, d >>= 1; // 将d处理为奇数
for (long long k = 0; k < 10; ++k) {
long long a = rand() % (p - 2) + 2;
long long x = quick_pow(a, d, p);
if (x == 1 || x == p - 1) continue;
for (int i = 0; i < r - 1; ++i) {
x = (__int128)x * x % p;
if (x == p - 1) break;
}
if (x != p - 1) return 0;
}
return 1;
}
long long Pollard_Rho(long long x) {
long long s = 0, t = 0;
long long c = (long long)rand() % (x - 1) + 1;
int step = 0, goal = 1;
long long val = 1;
for (goal = 1;; goal *= 2, s = t, val = 1) { // 倍增优化
for (step = 1; step <= goal; ++step) {
t = ((__int128)t * t + c) % x;
val = (__int128)val * abs(t - s) % x;
if ((step % 127) == 0) {
long long d = gcd(val, x);
if (d > 1) return d;
}
}
long long d = gcd(val, x);
if (d > 1) return d;
}
}
void fac(long long x) {
if (x <= max_factor || x < 2) return;
if (Miller_Rabin(x)) { // 如果x为质数
max_factor = max(max_factor, x); // 更新答案
return;
}
long long p = x;
while (p >= x) p = Pollard_Rho(x); // 使用该算法
while ((x % p) == 0) x /= p;
fac(x), fac(p); // 继续向下分解x和p
}
int main() {
scanf("%d", &t);
while (t--) {
srand((unsigned)time(NULL));
max_factor = 0;
scanf("%lld", &n);
fac(n);
if (max_factor == n) // 最大的质因数即自己
printf("Prime\n");
else
printf("%lld\n", max_factor);
}
return 0;
}